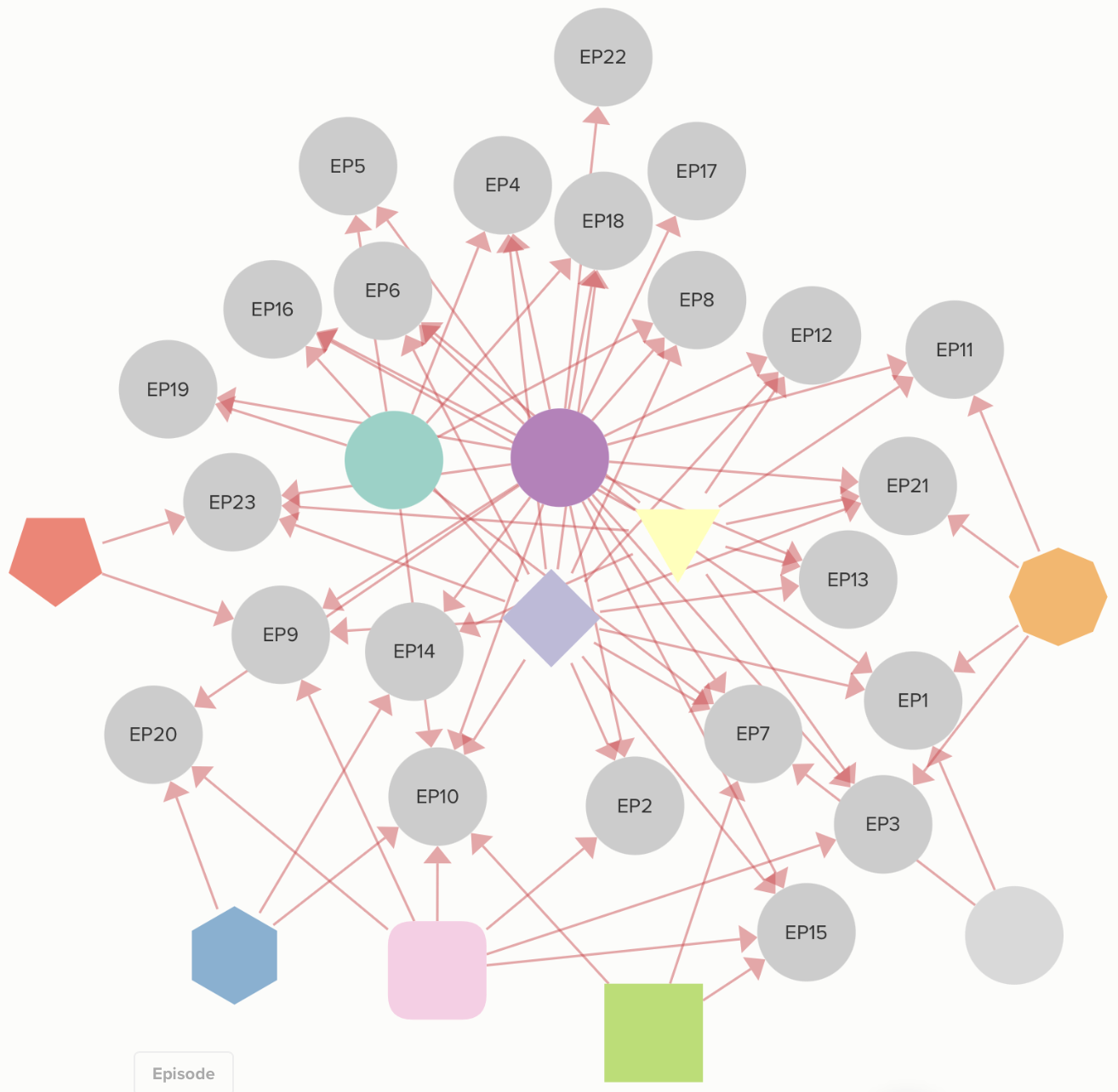
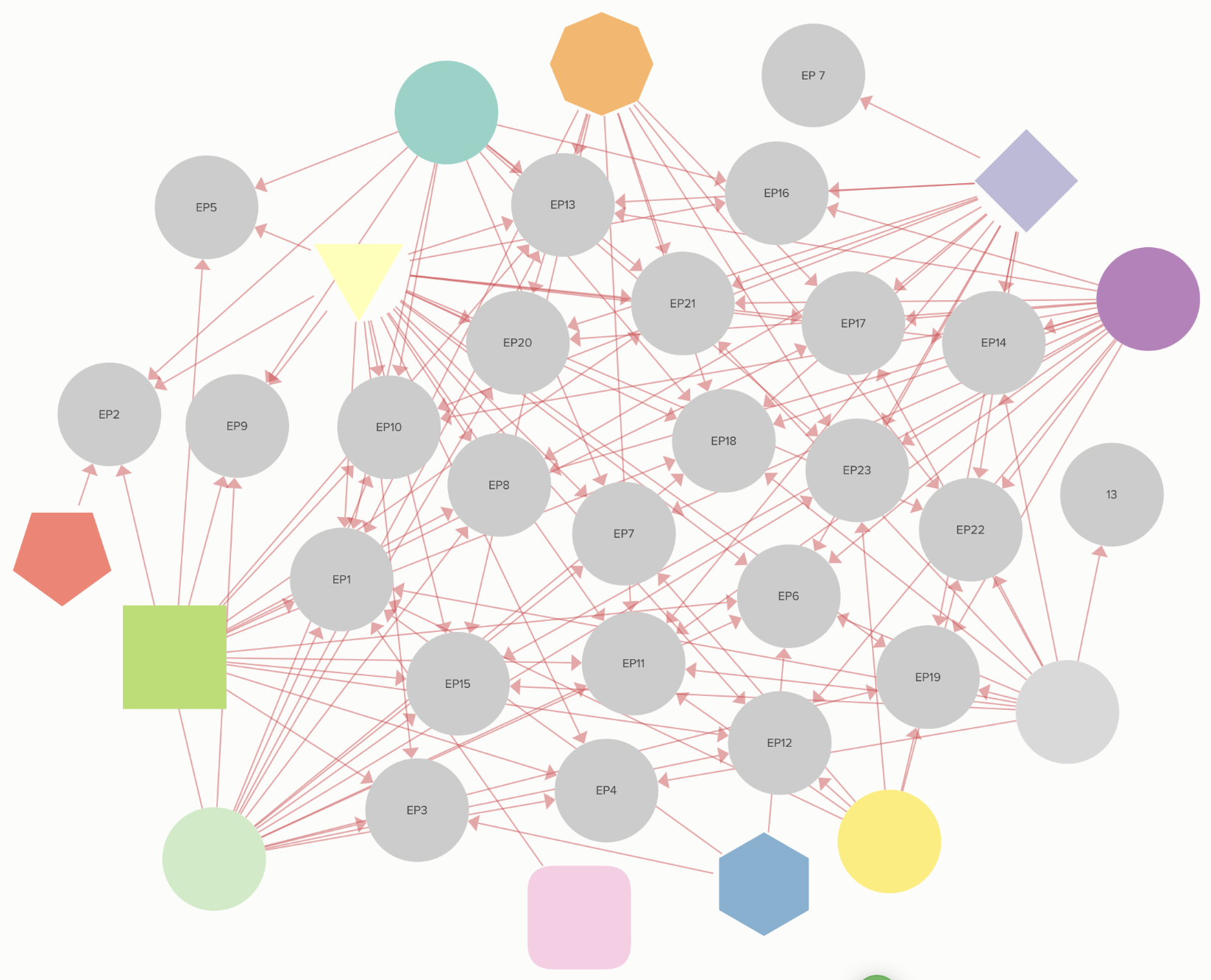
The two Kumu diagrams represent structured datasets related to two different searched
groups of words from the episodes. Each dataset consists of common words, main
characters’ names (first and last), their frequency of mentions, and the episodes in
which they appear. The first Kumu (word search) has a simpler structure with fewer
nodes and direct relationships, suggesting a straightforward, user-friendly network.
The second Kumu (name search) is more complex, with interconnected relationships
indicating a denser navigation structure that requires slightly more effort to
explore. Together, these maps highlight different levels of word and name
frequencies.
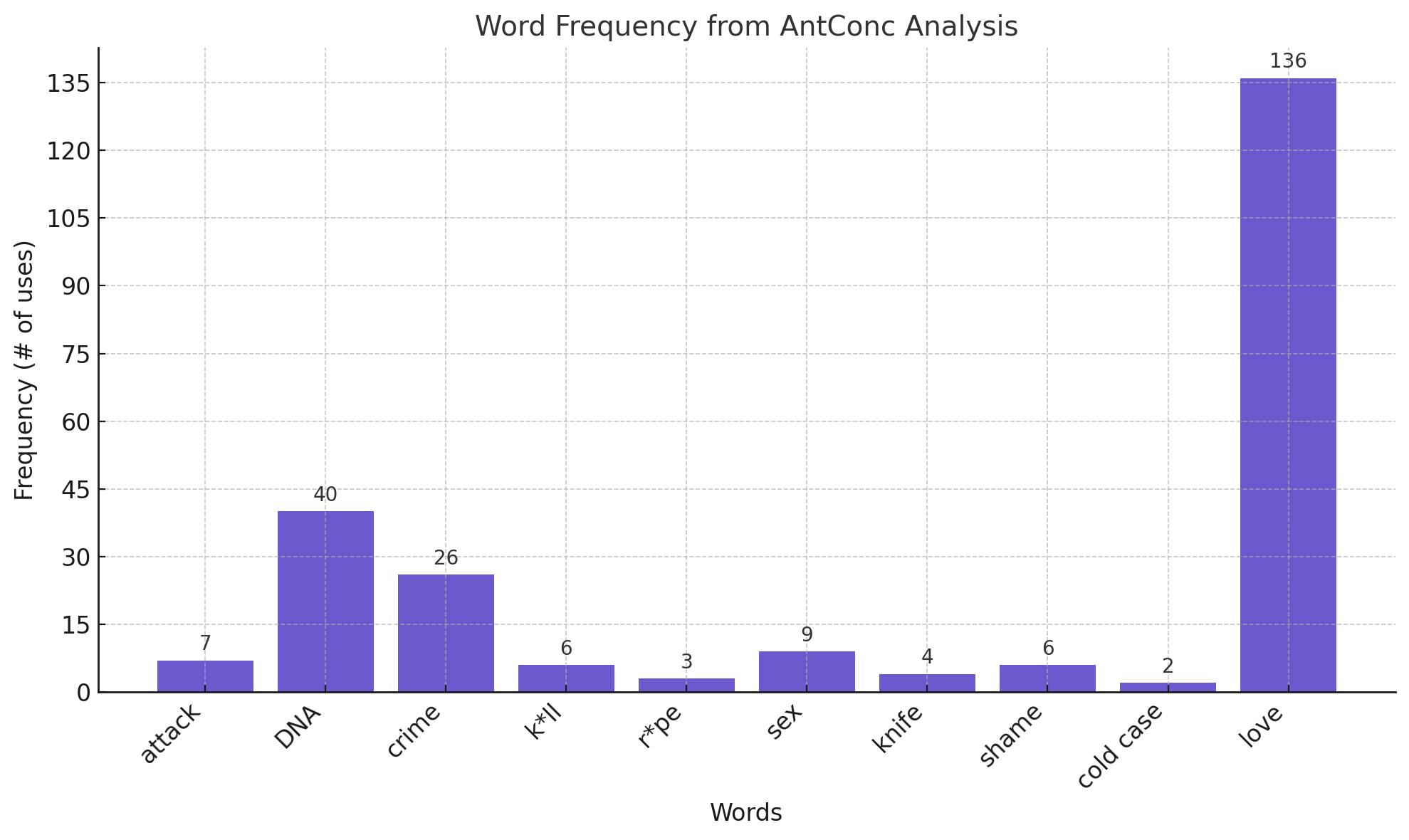
| Word |
Count |
Episodes |
| attack |
7 |
EP18, EP19, EP8, EP5, EP4, EP10, EP7 |
| DNA |
40 |
EP3, EP6, EP21, EP13, EP11, EP23, EP14, EP16, EP12 |
| crime |
26 |
EP7, EP23, EP21, EP12, EP15, EP6, EP18, EP9, EP13, EP2, EP1, EP8, EP10, EP4,
EP16 |
| k*ll |
6 |
EP23, EP9 |
| r*pe |
3 |
EP14, EP10, EP20 |
| sex |
9 |
EP3, EP21, EP11, EP1 |
| knife |
4 |
EP15, EP7, EP10 |
| shame |
6 |
EP15, EP20, EP9, EP10, EP2, EP3 |
| cold case |
2 |
EP7, EP1 |
| love |
136 |
EP23, EP7, EP15, EP11, EP20, EP10, EP21, EP13, EP4, EP14, EP5, EP6, EP17,
EP16, EP12, EP2, EP8, EP18, EP19, EP9, EP1, EP3, EP22 |
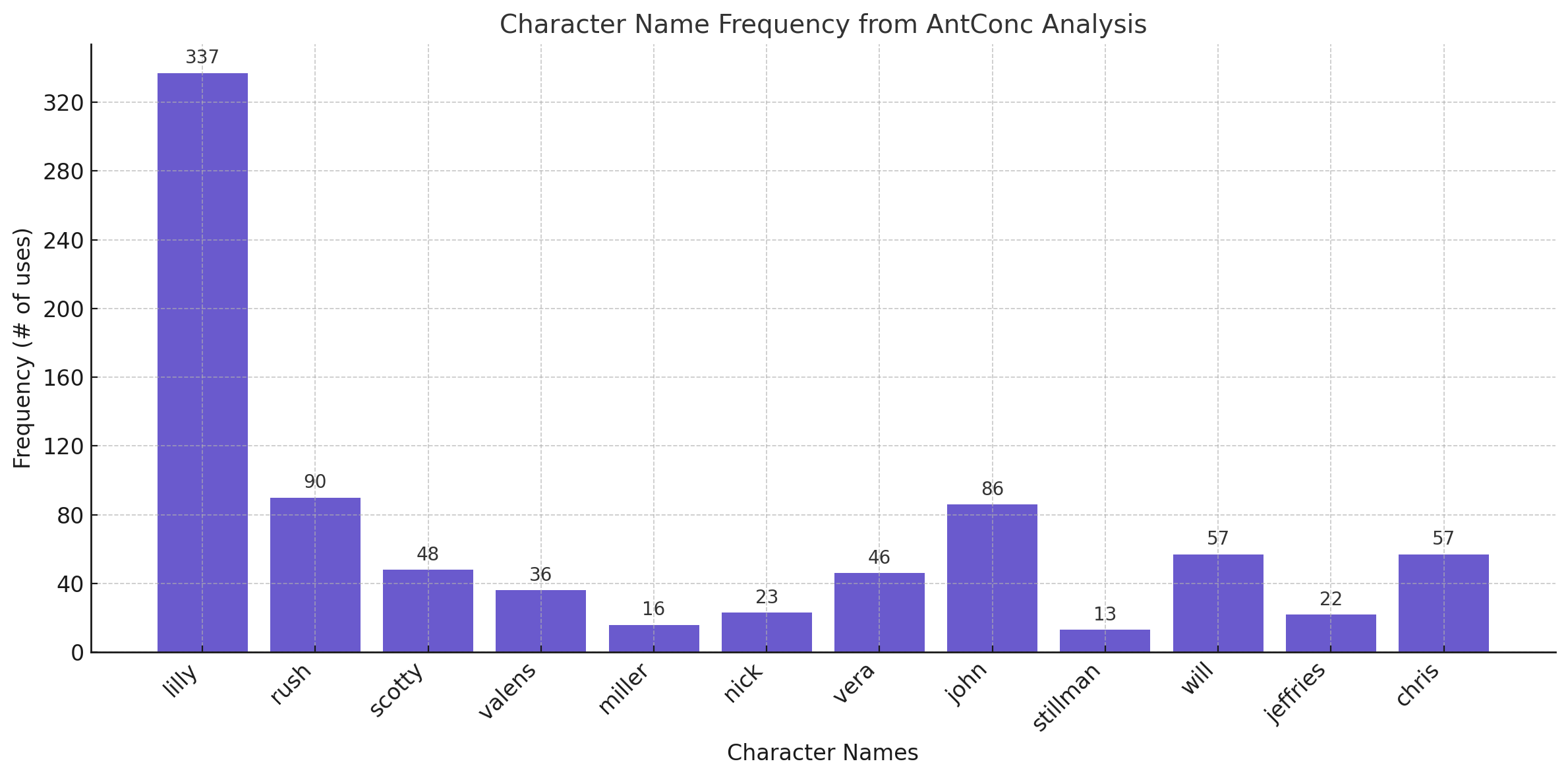
| Name |
Count |
Episodes |
| lilly |
337 |
EP1, EP21, EP16, EP18, EP9, EP10, EP7, EP13, EP5, EP23, EP2 |
| rush |
90 |
EP11, EP5, EP4, EP13, EP6, EP16, EP21, EP20, EP10, EP19, EP14, EP15, EP8,
EP2, EP1, EP7, EP9, EP3, EP12, EP17, EP18, EP22 |
| scotty |
48 |
EP10, EP6, EP20, EP14, EP22, EP19, EP13, EP8, EP17, EP21, EP18, EP7, EP11,
EP23, EP16 |
| valens |
36 |
EP17, EP10, EP21, EP6, EP20, EP11, EP23, EP8, EP16, EP18, EP22, EP7, EP13,
EP12, EP19, EP14, EP15 |
| miller |
16 |
EP2 |
| nick |
23 |
EP1, EP3, EP6 |
| vera |
46 |
EP4, EP10, EP18, EP6, EP12, EP2, EP15, EP1, EP3, EP23, EP13, EP19, EP9, EP8,
EP11, EP7, EP20 |
| john |
86 |
EP1, EP13, EP18, EP21, EP17, EP15, EP11, EP20, EP22, EP23 |
| stillman |
13 |
EP1, EP23, EP19, EP12, EP22, EP11, EP7 |
| will |
57 |
EP6, EP1, EP4, EP15, EP17, EP19, EP18, EP11, EP22, EP14, EP13, EP21 |
| jeffries |
22 |
EP12, EP6, EP13, EP8, EP4, EP10, EP15, EP5, EP1, EP17, EP9, EP3, EP21, EP11,
EP18 |
| chris |
57 |
EP1 |